
Harness-1: A 20B Search Agent with Externalized Memory and State
Harness-1 is out — a search agent with 20B parameters and a rather unusual idea.
Instead of forcing the model to keep the entire search history in context, the authors decided to externalize the state and train the model to operate through a special harness.
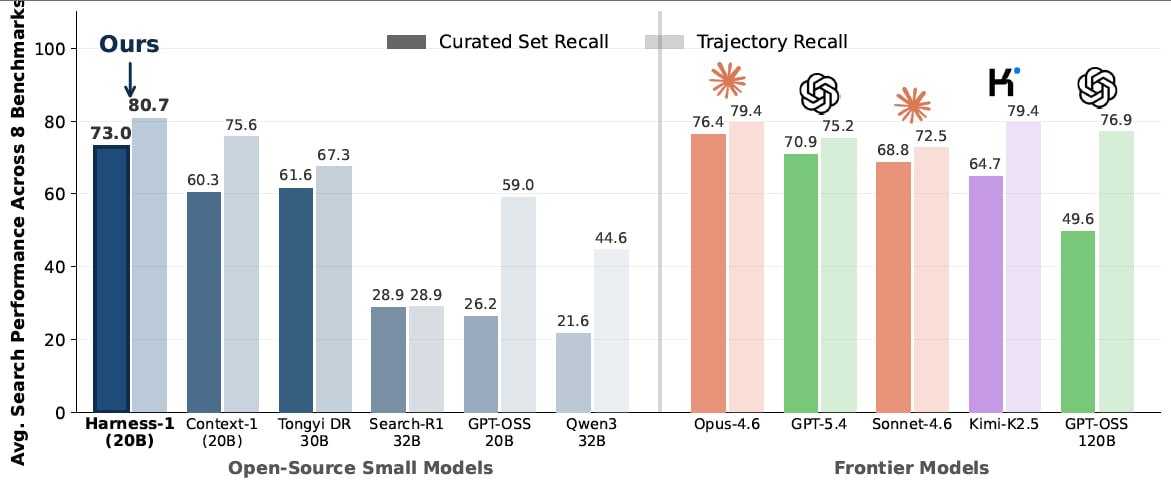
A 20B-parameter agent has been released that, on long search tasks, competes with much larger models.
Usually, search agents work like this:
search → reading → search → reading → everything gets added to the context.
As a result, the model simultaneously plays the role of search engine, memory, note-taker, verifier, and librarian.
Harness-1 separates these tasks.
The model still decides what to search for, what to read, which facts to store, and what to verify. But the entire search state is stored in an external harness layer.
It maintains the agent’s working memory:
• found documents
• selected evidence
• search history
• links between sources
• verification results
• deduplication and compression of data
• context budget control
It’s also interesting that the model was trained on a relatively small amount of data: only 899 SFT trajectories and RL on 3453 queries. The authors believe that a significant part of the required behavior can be moved into the harness itself, rather than baked into the model’s weights.
The most interesting result is transferability. On new benchmarks that the model did not see during training, the gain turned out to be even higher than on the original tasks.
Paper : arxiv.org/abs/2606.02373
Code :
Model :
HF Paper: https://huggingface.co/papers/2606.02373