
NVIDIA Nemotron 3 Ultra: 550B MoE Open-Weights Model for Agents
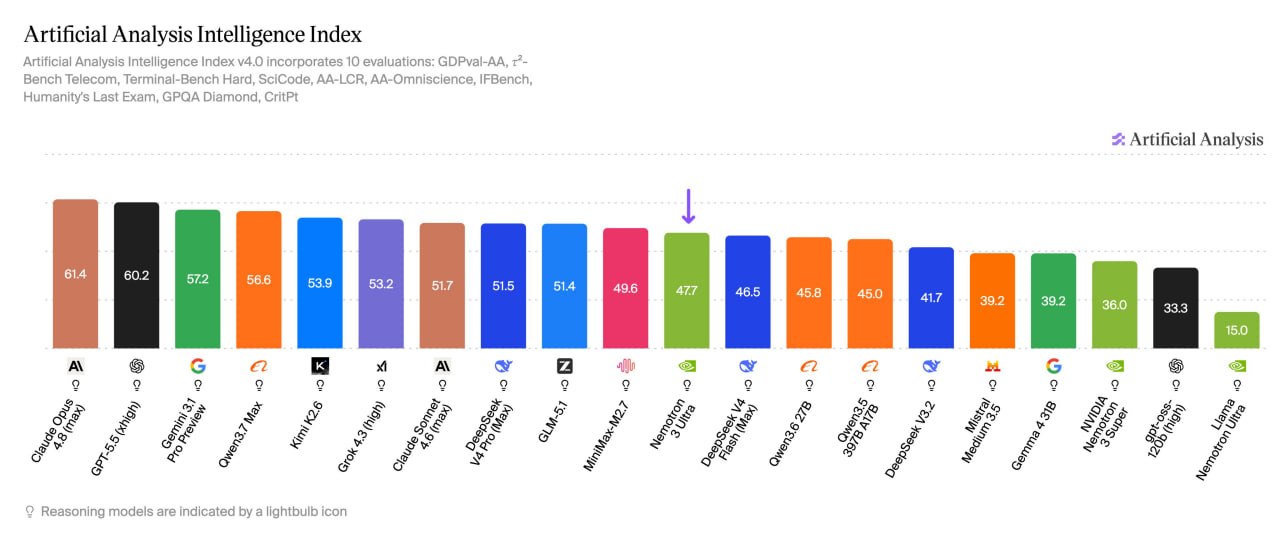
NVIDIA has released Nemotron 3 Ultra.
A 550B MoE model with open weights, tailored for long-lived agents.
According to NVIDIA:
• inference is up to 5× faster
• up to 30% cheaper on complex agent tasks
• stronger in programming, deep research, and long-term planning
The main focus is not on chats, but on agent scenarios where the model plans actions for hours, calls tools, handles errors, and makes decisions about next steps.
It uses a hybrid Mamba + Transformer MoE architecture, which makes it possible to run more reasoning cycles in the same amount of time.
Notable points:
• can work with large codebases
• maintains long chains of tool calls
• can collect and synthesize data from hundreds of sources
• was fine-tuned for OpenClaw, Hermes Agent, and LangChain
NVIDIA also opened not only the model weights, but also synthetic datasets along with post-training recipes.
And an immediate nice bonus.
Nous Research joined the Nemotron coalition and together with NVIDIA and Nebius opened free access to Nemotron 3 Ultra via Nous Portal for two weeks.
For those who want to run the model locally, GGUF quantizations from Unsloth have already appeared.
GGUF:
Guide: here