
Alibaba Qwen3.6-35B-A3B: Sparse MoE Model with 3B Active Params
Alibaba released Qwen3.6-35B-A3B today.
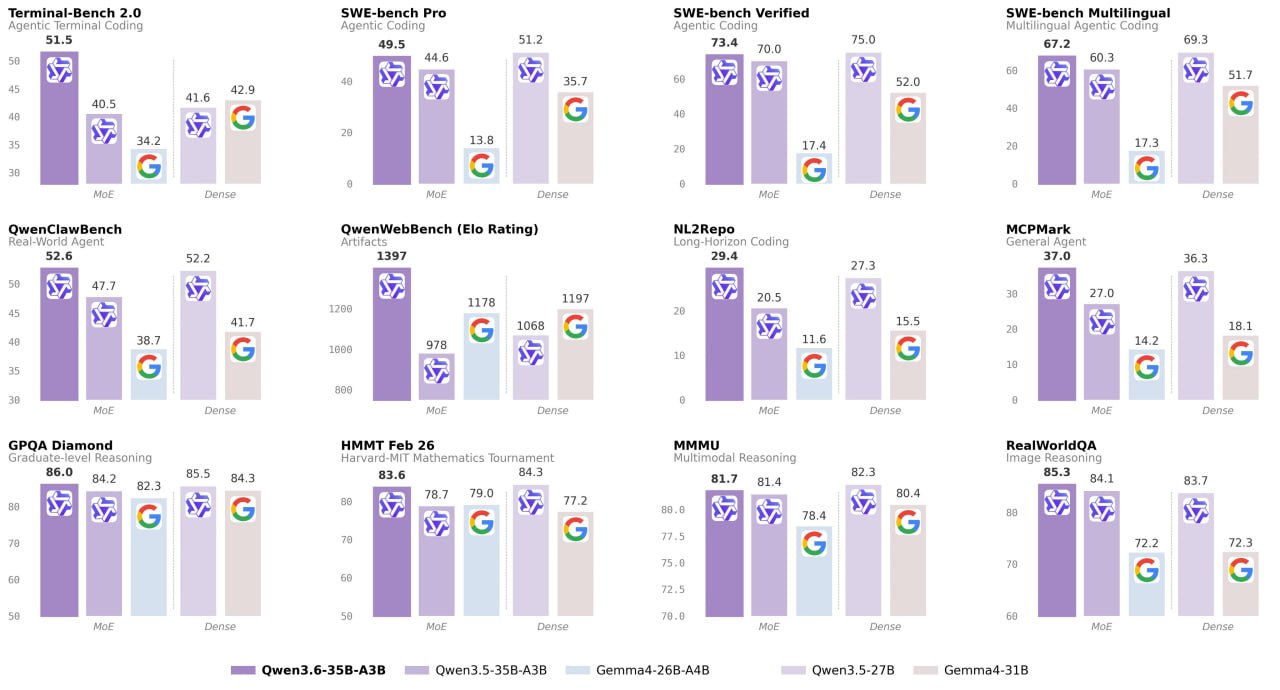
This is a sparse MoE: 35 billion parameters, with only 3 billion active.
It outperforms the dense model Qwen3.5-27B (27 billion parameters) on a number of key coding benchmarks and significantly surpasses its direct predecessor Qwen3.5-35B-A3B, especially in agentic coding and reasoning tasks.
Qwen3.6 is multimodal from the start, and Qwen3.6-35B-A3B demonstrates perception and multimodal reasoning capabilities that far exceed expectations for its size, with only ~3 billion active parameters.
On most vision-language benchmarks, its results are comparable to Claude Sonnet 4.5 and even surpass it on a number of tasks. Particularly notable are its strengths in spatial intelligence: 92.0 on RefCOCO and 50.8 on ODInW13.
Unsloth GGUF, so the model can be run locally on 23 GB RAM / Mac in 4-bit mode. (guide)