
Cerebras Kimi K2.6 Hits 981 tok/s, Beating Top GPUs in Inference
Cerebras launched Kimi K2.6 and outpaced every GPU in the world
California-based Cerebras Systems decided to seriously shake up the inference market and, in particular, nvidia, significantly undermining their position in the enterprise AI inference market.
They launched Kimi K2.6 with 1 trillion parameters and did it at record speed.
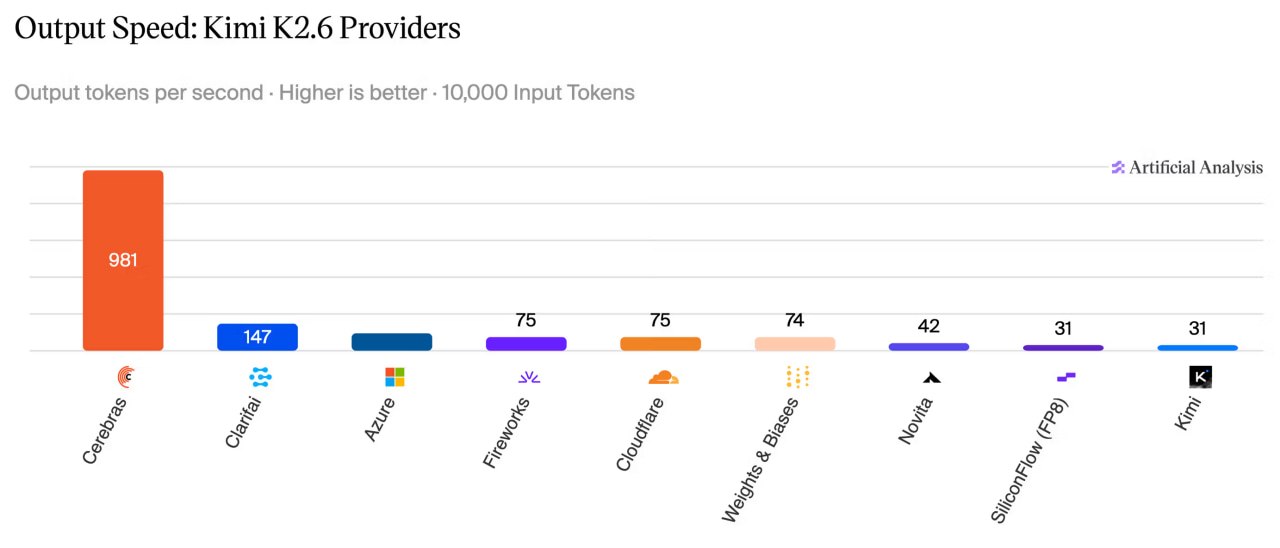
Independent Artificial Analysis recorded an output result of 981 tokens per second:
- 6.7× faster than the best cloud GPU provider
- 23× faster than the market average
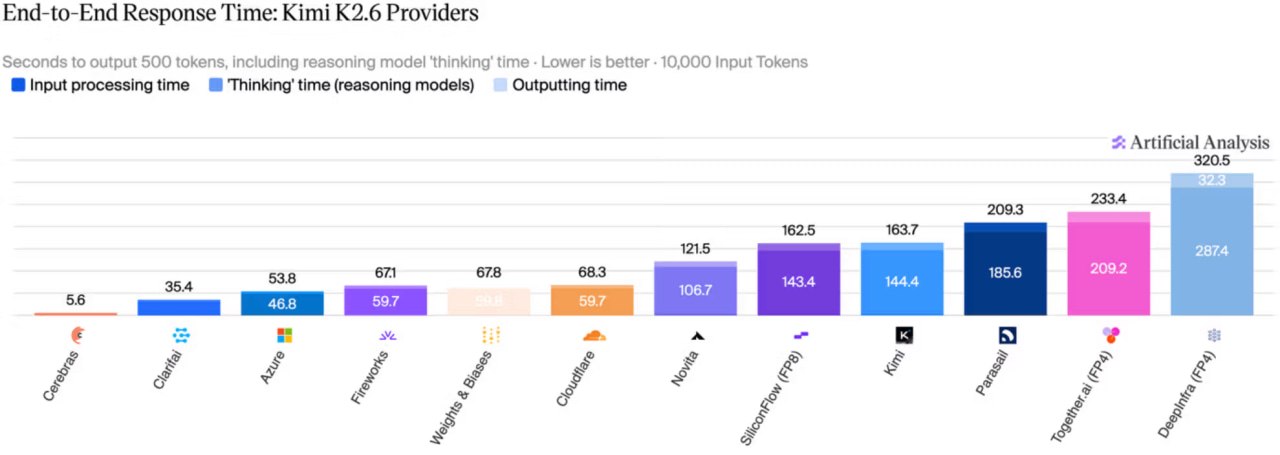
For context, a standard developer request with 10,000 input tokens and generation of 500 output tokens was processed by Cerebras in 5.6 seconds, while the official Kimi cloud service handled it in 163.7 seconds—a difference of almost 30×.
Cerebras uses the Wafer-Scale Engine 3, their unique single processor the size of a silicon wafer:
- inside: 44GB of ultra-fast on-die SRAM
- the bandwidth of the on-die network is 200× higher than Nvidia’s NVLink
- model weights are placed across ~20 CS-3 systems, but all MoE layer experts fit on a single wafer
For now, this is a closed enterprise cloud for Fortune 500–level clients. Pricing is in the mid-to-high range of GPU providers’ rates. The company compares itself to a powerful truck and doesn’t enter the cheap segment of slow inference (~20 tok/s).
By the way, there were recently deals about Nvidia acquiring Groq for $20 billion and a Cerebras contract with OpenAI worth over $20 billion, so the inference market is accelerating fast.
It’s interesting what happens next and who will be the first to decide to release such technologies into open access.